
Apache Spark
je open-source distribuovaný univerzální framework určený k provádění výpočtů na úrovni clusteru. Největší výhodou je právě možnost paralelizace na vysoké úrovni a dostupnosti v tzv. módu „High Availability“ (HA), neboli vysoká dostupnost. Díky těmto vlastnostem je Apache Spark naprosto ideální pro nasazení v prostředí pro zpracování velkého množství dat bez možnosti výpadku. Vysoké množství úloh lze spravovat současně na jedné platformě s minimálním úsilím právě díky centralizaci všech výpočetních úkonů či nástrojů v Apache Spark.
Spark se často používá u distribuovaných datových uložišť, jako jsou:
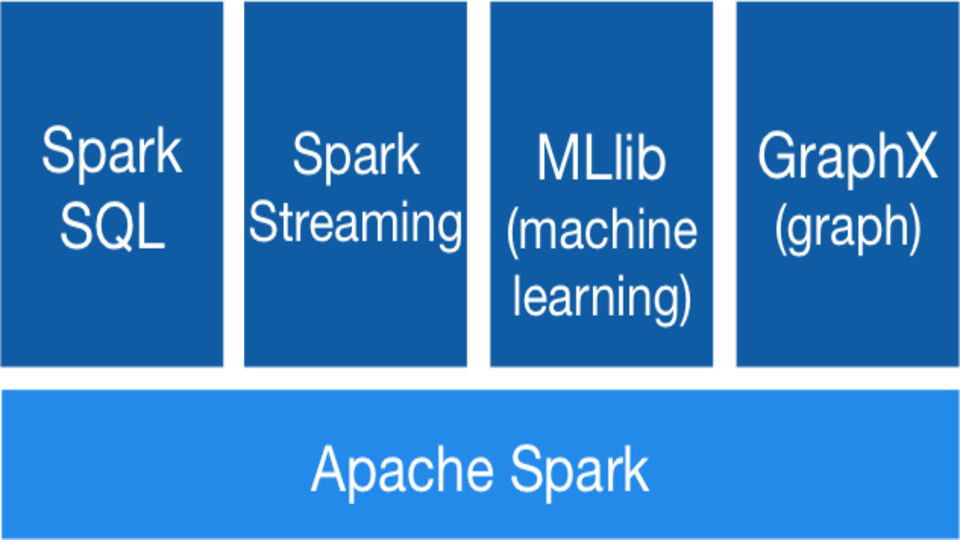
Apache Spark pracuje tzv. „in-memory“, neboli v paměti. Díky tomu mohou aplikace pracovat s daty až 100x rychleji, a to zmenšením množství operací čtení a zápisu na disk. Další výhodou je možnost využití více programovacích jazyků. Apache Spark umí nativně pracovat s jazyky Java, Scala anebo Python. Zároveň lze využít analytické možnosti Apache Spark, jedná se o:
- SQL dotazy,
- Machine Learning,
- Stream Data a práci s nástroji
- a algoritmy grafických nástrojů.
Spark a jeho účel
Spark je schopen zpracovat několik petabajtů dat najednou, distribuovaných do shluku tisíců spolupracujících fyzických nebo virtuálních serverů. Má rozsáhlou sadu vývojových knihoven a API a podporuje jazyky jako Java, Python, R a Scala. Díky své flexibilitě se dobře hodí pro řadu případů použití.
- MapR XD,
- Hadoop HDFS,
- Amazon S3,
- s populárními databázemi NoSQL, jako je Vertica,
- MapR Database,
- Apache HBase,
- Apache Cassandra,
- MongoDB,
- s distribuovanými streamovacími platformami pro zasílání zpráv, jako je MapR Event Store a Apache Kafka.
Zpracování datových toků:
Od souborů protokolu k datům senzorů se vývojáři aplikací stále více potýkají s „datovými proudy“ dat. Tato data přicházejí ve stálém proudu, často z více zdrojů současně. I když je jistě možné tyto datové toky ukládat na disk a analyzovat je zpětně, někdy může být rozumné nebo důležité zpracovávat a jednat s daty, jakmile dorazí. Například toky dat vztahující se k finančním transakcím mohou být zpracovány v reálném čase pro identifikaci – a odmítnutí – potenciálně podvodných transakcí.
Strojové učení:
S rostoucím objemem dat se přístupy strojového učení (Machine Learning) stávají reálnějšími a stále přesnějšími. Software může být vyškolen tak, aby identifikoval a jednal dle eventů v dobře srozumitelných souborech dat a působil před použitím stejných řešení na nová a neznámá data. Schopnost Sparku ukládat data do paměti a rychle spouštět opakované dotazy z něj činí dobrou volbu pro tréninkové algoritmy strojového učení. Spouštění podobných dotazů znovu a znovu v distribuovaném prostředí významně zkracuje čas potřebný k procházení sadou možných řešení za účelem nalezení nejúčinnějších algoritmů.
Interaktivní analytika:
Obchodní analytici a vědci s údaji chtějí spíš než předdefinované dotazy vytvářet statické řídicí panely:
- produktivity prodejních nebo výrobních linek nebo cen akcií,
- zkoumat svá data položením otázky,
- prohlížením výsledku a následným změněním počáteční otázky nebo hlouběji analyzovat výsledky.
Tento proces interaktivního dotazování vyžaduje systémy, jako je Spark, které jsou schopné rychle reagovat a přizpůsobit se.
Integrace dat:
Data vytvářená různými systémy v rámci podniku jsou zřídka čistá nebo konzistentní natolik, že je lze snadno a lehce kombinovat pro reporting nebo analýzu. Procesy extrakce, transformace a načtení (ETL) se často používají k získávání dat z různých systémů:
- k jejich čištění,
- standardizaci,
- a poté k načtení do samostatného systému pro analýzu.
Spark (a Hadoop) se stále více používají ke snižování nákladů a času potřebného pro tento proces ETL.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}