
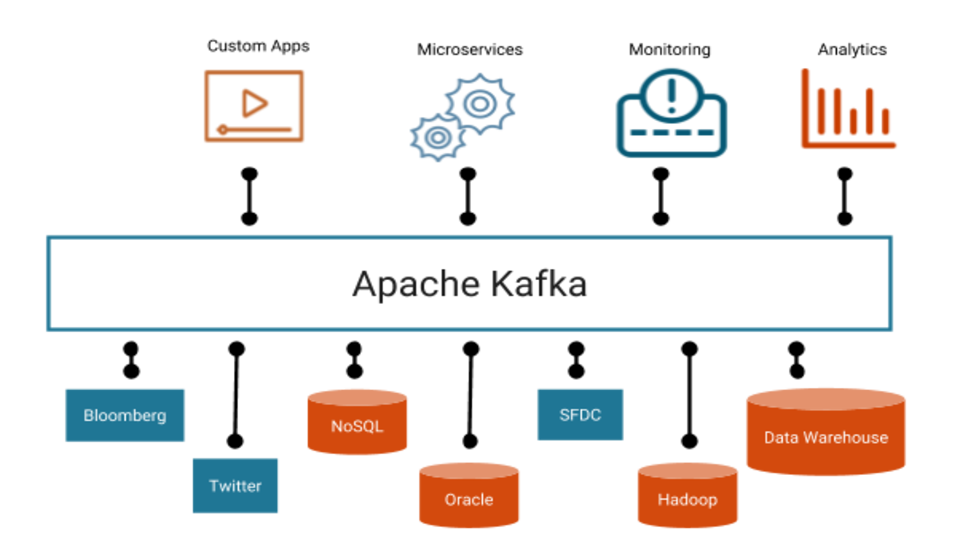
Apache Kafka
je open-source distribuovaná streamovací platforma s vysokou propustností a nízkou latencí pro zpracování datových toků v reálném čase.
Jako streamovací platforma nabízí Kafka tyto schopnosti:
- Publikování a přihlášení se k odběru streamů záznamů, podobných frontám zpráv.
- Trvalé ukládání stream záznamů způsobem odolným proti chybám.
- Zpracování stream záznamů v okamžiku jejich výskytu.
Jedním z nejčastější využití platformy Kafka je vytvoření streamovacích datových cest pro přenos dat mezi různými systémy a aplikacemi v reálném čase. Dalším častým využitím platformy Kafka je vytvoření streamovacích aplikací, které transformují nebo určitým způsobem reagují na data, taktéž v reálném čase.
Jak funguje Kafka je popsáno v následujících krocích
- Kafka je spuštěna jako cluster na jednom nebo více serverech, které mohou pokrývat více datových center.
- Klastr Kafka ukládá streamy záznamů do kategorií zvaných témata.
- Každý záznam se skládá z klíče, hodnoty a časového razítka.
Kafka má 4 základní API
- Producer API umožňuje aplikaci publikovat stream záznamů k jednomu nebo více tématům.
- Consumer API umožňuje aplikaci přihlásit se k odběru jednoho nebo více témat a zpracovat stream záznamů.
- Streams API umožňuje aplikaci fungovat jako procesor toku, použije vstupní stream z jednoho nebo více témat a produkuje výstupní stream do jednoho nebo více výstupních témat, čímž účinně transformuje vstupní stream na výstupní stream.
- Connector API umožňuje vytvářet a provozovat opakovaně použitelné publikace nebo odběry, které propojují témata Kafka se stávajícími aplikacemi nebo datovými systémy. Například spojení na relační databázi může zachytit každou změnu tabulky.
V Kafka platformě probíhá komunikace mezi klienty a servery pomocí jednoduchého, vysoce výkonného, jazykově agnostického protokolu TCP. Nativní Java klient pro Kafku není jediný. Klient pro Kafku je napsán v mnoha dalších jazycích (C/C++, Python, .NET, PHP a další).
Stručně řečeno, Kafka se používá pro zpracování streamů, sledování aktivity webových stránek, shromažďování a monitorování metrik, agregaci protokolů, analytiku v reálném čase, přijímání dat do Spark, přijímání dat do Hadoop, opakované zprávy, obnovu chyb a zaručené distribuovaný commit protokol pro výpočet v paměti.
Kafka cluster si uchovává všechny publikované záznamy. Pokud nenastavíte limit, bude uchovávat záznamy, dokud nedojde místo na disku. Můžete nastavit časové limity (konfigurovatelné období uchování), limity založené na velikosti (konfigurovatelné podle velikosti) nebo zhutnění (udržuje klíčovou nejnovější verzi záznamu). Můžete například nastavit zásady uchování na tři dny nebo dva týdny nebo měsíc. Záznamy v protokolu témat jsou k dispozici pro odběr, dokud nejsou vyřazeny podle času, velikosti nebo zhutnění. Rychlost odběru není ovlivněna velikostí, protože Kafka vždy píše na konec protokolu témat.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}