
Platforma konvergovaných dat: Co z toho mají vývojáři?
Často se diskutuje o datech a jejich důležitosti, ale jaká je skutečná hodnota dat? Co je důležitější: Nezpracovaná data nebo informace skryté v nezpracovaných datech? Jak získáváte informace ze všech dat? Chcete-li odemknout informace skryté ve vašich datech, musíte se podívat na data ze všech zdrojů dat ze všech možných dimenzí. Největší [...]

Výkonnostní důsledky reflexe Java
Reflexe zpomaluje váš kód Java, proč tomu tak je? Reflexe je mocná – a často nepochopená. Tento článek bude stavět na představení Core Reflection API představeném v „Reflection for the modern Java programmer“, bude o dvou hlavních tématech: jak je reflexe implementována v HotSpot JVM a změny provedené v reflexi v [...]

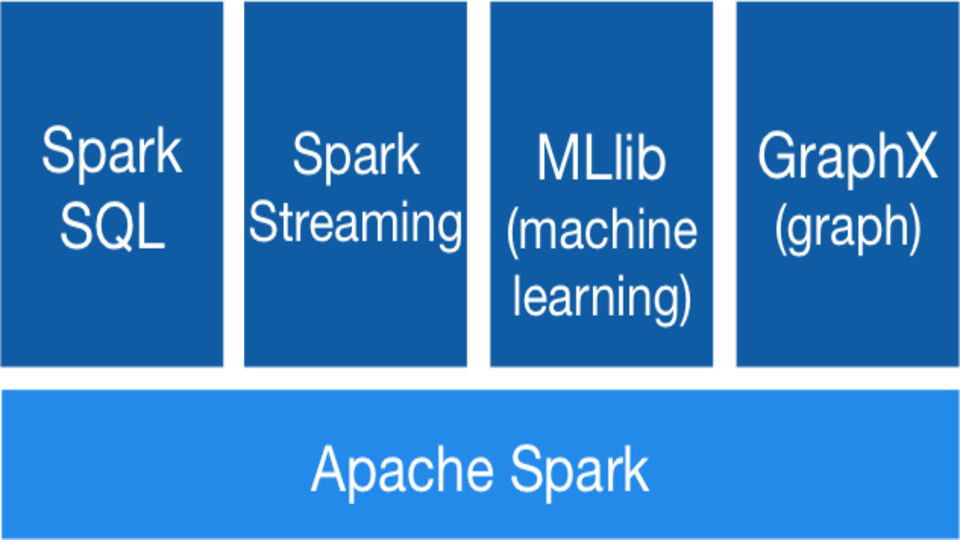
Spark na cluster chytře
Apache Spark je open-source distribuovaný univerzální framework určený k provádění výpočtů na úrovni clusteru. Největší výhodou je právě možnost paralelizace na vysoké úrovni a dostupnosti v tzv. módu „High Availability“ (HA), neboli vysoká dostupnost. Díky těmto vlastnostem je Apache Spark naprosto ideální pro nasazení v prostředí pro zpracování velkého množství dat [...]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
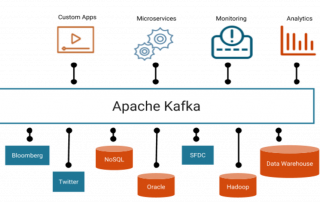
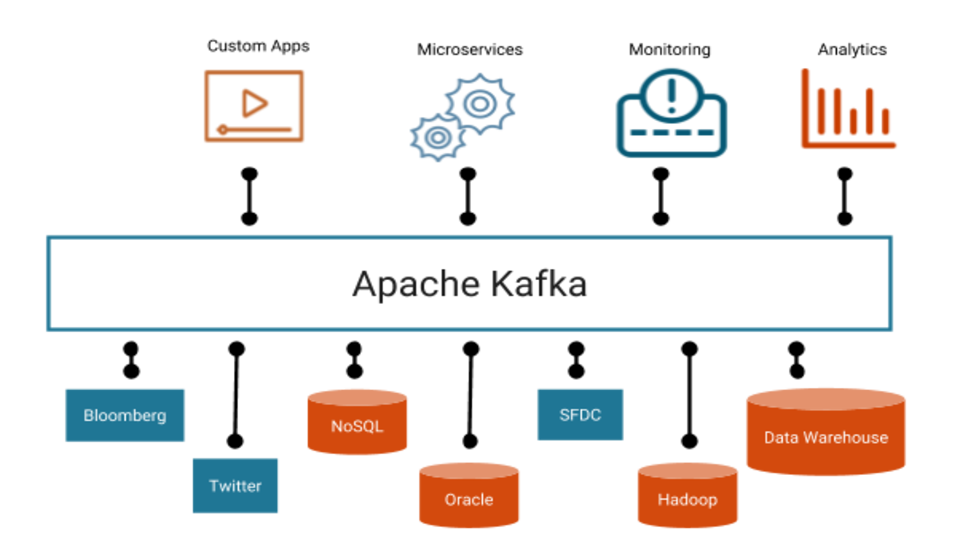
Představujeme Apache Kafka pro zpracování datových toků v reálném čase
Apache Kafka je open-source distribuovaná streamovací platforma s vysokou propustností a nízkou latencí pro zpracování datových toků v reálném čase. Jako streamovací platforma nabízí Kafka tyto schopnosti: Publikování a přihlášení se k odběru streamů záznamů, podobných frontám zpráv. Trvalé ukládání stream záznamů způsobem odolným proti chybám. [...]