


Před několika týdny publikoval Kirk Pepperdine fascinující výkonnostní výzvu – malý úryvek kódu v Javě, který se zdál triviální, ale za běhu produkoval záhadné chování.
Vyzval čtenáře, aby se o jeho vyřešení pokusili. Pokud jste ho ještě neviděli, zastavte se na chvíli a zkuste to sami – a až budete hotovi, podívejte se na Kirkovo oficiální řešení.
Když jsem to viděl, myslel jsem si, že by bylo zábavné si připomenout některé základy – ale čím hlouběji jsem se do toho pouštěl, tím víc jsem si uvědomoval, že nejde jen o výkon. Jde o to, jak myslíme.
Donutilo mě to zamyslet se nad tím, jak často my, jako vývojáři, nevědomky obchodujeme s efektivitou za pohodlí – a kolik z naší infrastruktury, výpočetní energie a dokonce i plýtvání energií nepochází ze špatné architektury, ale z malých, nevinných kódovacích rozhodnutí.
Všichni rádi mluvíme o optimalizaci nákladů na cloud – jak ušetřit 30%, 40%, možná i 50% úpravou konfigurací AWS nebo přesunem úloh na spotové instance (nebo ne). Ale jen zřídka si klademe jednodušší otázku:
Co když náš software už teď plýtvá 1000× více zdroji, než by měl?
To je skutečné umění ladění výkonu – ne honit se za milisekundami, ale vidět, kde jsme slepí k neefektivitě.
1. Rychlé zhodnocení reality – Programovací jazyky a energie
Pozoruhodná studie porovnávající energetickou účinnost 27 programovacích jazyků kvantifikovala to, co mnozí z nás intuitivně vědí: volba jazyka je důležitá – nejen kvůli rychlosti, ale i kvůli dopadu na životní prostředí.
| Jazyk | Spotřeba energie vs. C | Relativní výkon | Typické použití |
|---|---|---|---|
| C | 1x | Základní hodnota | Systémy, vestavěné |
| C++ | 1,2x | Téměř rodný | Vysoce výkonné systémy |
| Jáva | ~1,5–2x | JIT kompilován | Podnik, backend |
| Krajta | ~50x | Interpretováno | Skriptování, umělá inteligence, strojové učení |
| Ruby/PHP | ~40x | Interpretováno | Webový backend |
To není překlep – pro úplně stejný algoritmus dokáže Python spotřebovat 50× více energie než C. Java se nachází někde mezi tím – ale to je jen tehdy, když píšeme efektivní kód. Špatně napsaná Java se může snadno chovat jako skriptovací jazyk po předávkování kofeinem.
A měřítko všechno znásobuje.
Dokonce i Google se vší svou sofistikovaností hardwaru zaznamenal obrovské úspory, když optimalizoval místo rozšiřování pomocí umělé inteligence DeepMind, která snížila energii chlazení datových center až o 40 % a celkovou energii přibližně o 15%.
Ne nákupem dalších serverů, ale chytřejším přemýšlením o tom, jak stávající systémy využívají zdroje. Přesto mnoho z nás dělá pravý opak. Vytváříme mikroslužby v dynamických, interpretovaných jazycích a pak trávíme měsíce dolaďováním pravidel automatického škálování, abychom udrželi náklady na snesitelné úrovni. Škálujeme horizontálně místo vertikální optimalizace, přidáváme uzly spíše než vylepšujeme logiku.
O tom je tento článek – o tom, jak odlišné myšlení o kódu může pro výkon (a náklady) udělat více než veškeré ladění hardwaru na světě.
2. Krok jedna – Výjimky jako logika
Naivní základní stav vypadal takto:
public static boolean checkIntegerOrg(String testInteger)
Vypadá to rozumně, že? Pokud řetězec není číslo, zachytíme výjimku a pokračujeme dál. Jednoduché.
Jenže to tak není.
V datové sadě, kde mnoho vstupů nejsou čísla, si tento kód vede hrozně. Každý neplatný vstup spustí výjimku NumberFormatException a každá výjimka v Javě s sebou nese vysokou cenu. Vyvolání výjimky není jako vrácení hodnoty. Vytvoří plnohodnotný objekt, zachytí trasování zásobníku a synchronizuje se s interními funkcemi JVM. CPU tráví více času vedením účetnictví než vykonáváním užitečné práce.
Kolega nám jednou řekl: „Naše validační vrstva běží pomaleji než naše databázové dotazy." Když jsem se podíval, každý jednotlivý špatný záznam vyvolával – a protokoloval – výjimku. Aplikace nebyla vázána na I/O operace; byla vázána na výjimky. A takto se chová mnoho reálných systémů – neviditelná neefektivita maskovaná jako čistě vypadající kód.
Používání výjimek pro logiku je jako volání sanitky, abyste zkontrolovali, zda máte puls – technicky vzato správné, ale hrubě neefektivní.
A zde začíná celá cesta – tři datové sady, každá z nich je nepřehlednější než předchozí, s větším počtem nesprávných nebo chybně formátovaných záznamů [obrázek 1].
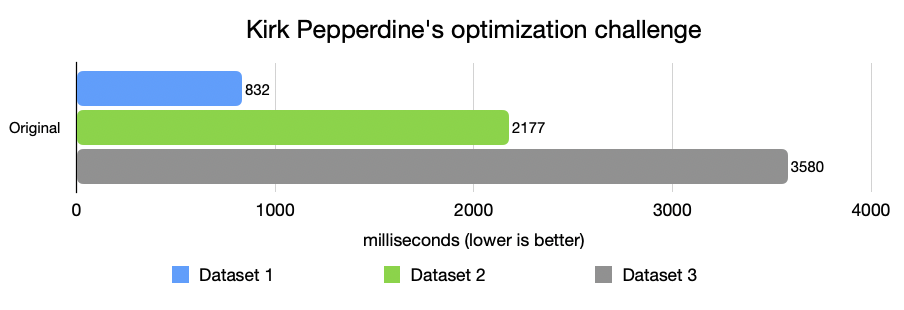
3. Druhý pokus – Past s regulárními výrazy
Odhodlaný to napravit, jsem si pomyslel: Zkusme vstupy před jejich analýzou prostě validovat. Přirozeně jsem sáhl po regulárních výrazech:
public static boolean checkIntegerRegExp(String testInteger)
Vypadalo to elegantně a bezpečně. A bylo to pomalejší. Mnohem pomalejší [obrázek 2].
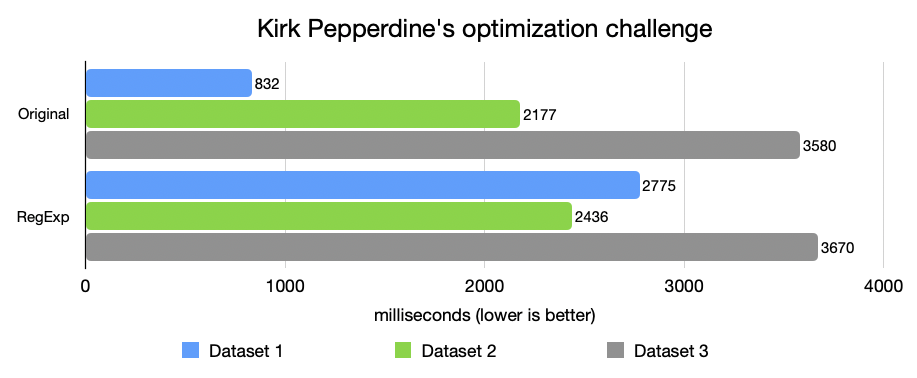
Proč může být RegExp trojský kůň
Proč? Protože pokaždé, když se spustí funkce matches(), spustí se pod kapotou malý stavový automat – který parsuje vzor, kompiluje ho, vytváří porovnávač a prochází vstupem znak po znaku. Pokud to děláte v aktivní cestě – jako je validace, parsování nebo filtrování požadavků – váš procesor stráví více času dekódováním syntaxe regulárních výrazů než kontrolou skutečných znaků.
Jeff Atwood na to varoval už dávno ve svém blogovém příspěvku Regex Performance. Popsal, jak regex enginy mohou snadno způsobit masivní zpomalení – a někdy dokonce způsobit „katastrofální backtracking", který zablokuje celá vlákna.
V jednom z mých vlastních projektů se regulární výraz určený k filtrování neplatných ID při zátěži stal pecí pro CPU. Jeho nahrazení jednoduchou smyčkou typu char zkrátilo čas CPU o 90%. Regulární výrazy jsou praktické.
Regexe jsou v SQL jako zástupné znaky – v pořádku pro pár záznamů, nebezpečné ve velkém měřítku – v reálném produkčním kódu vykazují řádové zpomalení.
4. Krok tři – Nechte CPU dýchat
Dále jsem zkusil něco jednoduššího. Co kdybychom prostě použili to, co Java už nabízí – bez magie regexů nebo pastí s výjimkami?
public static boolean checkIntegerIsDigit(String testInteger)
Výkon se okamžitě zlepšil – o řád [obrázek 3].
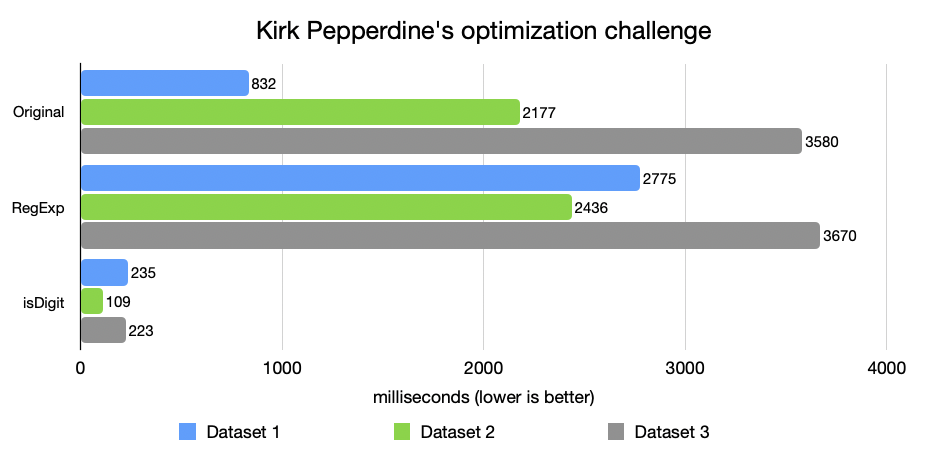
Proč? Protože CPU miluje předvídatelnost.
Logika je jednoduchá a předvídatelná. Větve se snadno spekulují, přístup k paměti je sekvenční a neexistují žádné skryté alokace. Žádné výjimky, žádné regex enginy, žádné vytváření objektů. Jen čistá, deterministická práce.
Stojí za to vědět, co váš jazyk již nabízí.
Další lekce: znát svou standardní knihovnu. Metody jako Character.isDigit() nebo Integer.parseInt() existují z nějakého důvodu – často je píší lidé, kteří strávili roky vyždímáním každé nanosekundy z JVM. Není vždy nutné znovu vynalézat kolo. Někdy je použití toho, co už existuje, rychlejší a bezpečnější.
I když nejsou dokonalé, pro většinu případů stačí a umožňují vám rychle vytvářet výkonný a udržovatelný kód.
Jak mi jednou řekl jeden vedoucí inženýr:
„Dobrý kód není nejkratší cestou k řešení – je to cesta s nejmenším počtem překvapení pro CPU a pro vývojáře."
5. Krok čtyři – Ruční preciznost
Ale chtěl jsem vědět, jak daleko to můžu dotáhnout. Tak jsem odstranil i ty vestavěné funkce a napsal vlastní verzi:
public static boolean checkIntegerCustomIsDigit(String testInteger)
public static int fastParseInt(String s)
Tato ručně vytvořená verze byla zhruba 2× rychlejší než Character.isDigit(). Proč? Žádná volání metod, žádná režie Unicode, žádné irelevantní kontroly [obrázek 4].
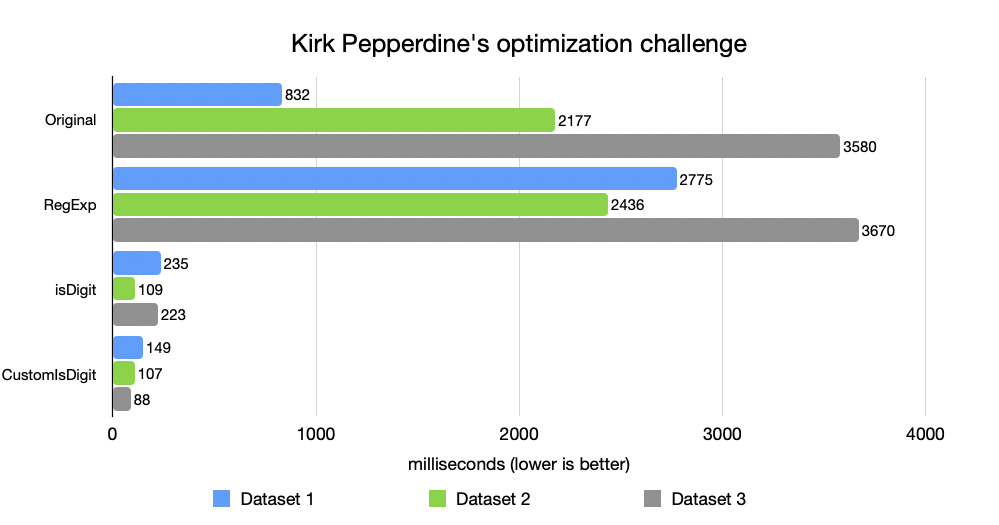
Toto vylepšení ale přišlo s kompromisem. Kód byl méně obecný, méně odolný vůči budoucím změnám a o něco hůře čitelný. Podobné vzorce jsem viděl i v produkčním prostředí. V jednom finančním systému s nízkou latencí jsme nahradili Integer.parseInt() v kritické cestě, která zpracovávala miliony zpráv za sekundu. Zisk byl 300 ms na milion zpráv. Triviální v izolaci, transformativní v globálním měřítku.
Přesto existuje tenká hranice mezi precizností a posedlostí. Někdy je nejvíce optimalizovaný kód také nejméně udržovatelný. Optimalizace by měla sloužit systému, ne egu.
Kdy má tato úroveň optimalizace smysl?
- Horké cesty: analýza milionů záznamů, validace sítě nebo příjem dat.
- Známá omezení: ASCII číslice, pevné délky.
- Masivní rozsah: malé neefektivnosti se násobí.
Takové optimalizace však s sebou nesou určité náklady: větší složitost, menší univerzálnost. Používejte je záměrně, ne ze zvyku.
6. Krok pátý – Selhejte rychleji, myslete chytřeji
Nakonec jsem vytvořil verzi, která rychle selhala, nejdříve jsem zkontroloval nejjednodušší podmínky a vynechal zbytečnou práci.
public static boolean checkIntegerFinal(String testInteger)
Tato verze poskytovala 10× až 50× lepší výkon než originál – téměř shodný s Kirkovou vlastní rozvinutou variantou s přepínačem (na obrázku 5 označenou jako Nejlepší).
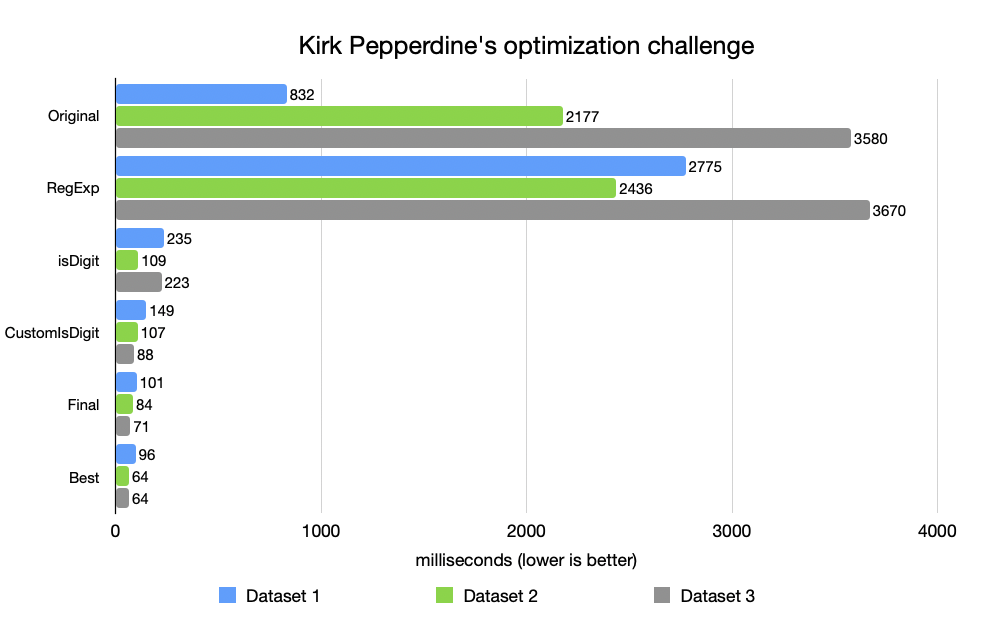
V tu chvíli jsem si uvědomil jednu věc: Samotný proces optimalizace učí víc než konečný výsledek. Každý krok – odstranění výjimek, nahrazení regulárních výrazů, zjednodušení smyčky – odlupoval vrstvy odpadu. Výsledkem nebyl jen rychlejší kód. Bylo to jasnější myšlení.
7. Ekonomika efektivity
Cloudové výpočty nám dávají nekonečnou škálovatelnost – a nekonečné pokušení ignorovat plýtvání.
- Řešíme problémy hardwarem.
- Místo analýzy automaticky škálujeme.
- Neefektivitu „monitorujeme", místo abychom ji eliminovali.
Neefektivita ale v cloudu nezmizí – spíše se znásobuje. Každý další procesorový cyklus běží na tisících počítačů v desítkách regionů.
Místo optimalizace se škálujeme. Místo pochopení se „automaticky léčíme". Spoléháme se na větší stroje místo na lepší kód.
Jedním z nejjednodušších reálných způsobů, jak snížit náklady na cloud, není přepisování kódu – jde o jeho spouštění v lepším běhovém prostředí. Vezměte si jako příklad rozsáhlá nasazení Kafka. V benchmarku samotného Azulu poskytl Apache Kafka na Azul Platform Prime přibližně o 45% vyšší maximální propustnost a zhruba o 30% vyšší využitelnou kapacitu při stejné SLA s latencí P99 ve srovnání s klasickým OpenJDK. Pokud zachováte stejnou pracovní zátěž a SLA, tento výkonnostní prostor se promítá do přibližně o 30–40% méně brokerů potřebných k provedení stejné práce – a tedy o 30–40% nižších nákladů na infrastrukturu Kafka (výpočetní, úložné, síťové a provozní režie). Jinými slovy, pouhá změna JVM může přinést úspory, které většina týmů usiluje měsíce laděním instancí a vyjednáváním o rezervované kapacitě.
Když WhatsApp převzal Facebook, obsluhovalo ho přes 450 milionů uživatelů s pouhými 35 inženýry. To není magie – to je inženýrská disciplína, posedlost efektivitou a běhové prostředí optimalizované pro souběžnost.
Efektivita se týká i lidí, nejen obsluhy.
Nejlevnější optimalizace je ta, která se provede před nasazením.
Skrytý účet za energie
Výpočet se rovná energii. Plýtvání softwarem tiše zvyšuje uhlíkovou stopu.
Optimalizovaný kód není jen levnější – je ekologičtější. Efektivita a udržitelnost cloudu začínají na klávesnici, nikoli na fakturačním dashboardu.
8. Umění, ne algoritmus
Ladění výkonu není ani tak o syntaxi a více o řemeslném zpracování. Jde o zvědavost, smysl pro detail a respekt ke stroji. Jde o to vidět krásu v přesnosti a hospodárnosti pohybu.
Dobře vyladěná funkce je jako haiku: stručná, vyvážená, záměrná.
Skutečná výkonnostní práce není o úsporách milisekund – jde o všímavost v kódu.
Knuth napsal knihu Umění počítačového programování, nikoli Věda, z nějakého důvodu: věda definuje, co je možné; umění rozhoduje o tom, co má smysl.
Každá optimalizace něco stojí. Trik spočívá v tom, vědět, které náklady se vyplatí platit.
9. Závěrečné myšlenky – kód jako řemeslo
Moje finální implementace nebyla dokonalá. Kirkova byla stále o něco rychlejší. Ale o to nejde. Jde o to, že softwarový odpad je neviditelný, dokud ho nezměříte. Neefektivitu jsme normalizovali, protože cloud ji skrývá za elasticitou. Říkáme tomu odolnost, ale často se jedná jen o nadměrné zřizování.
Jeden mentor mi jednou řekl,
„Pokud dokážete problém s výkonem vyřešit penězi, není vyřešen – je odložen."
A měl pravdu. Úspora 30% na účtě za cloud moc neznamená, pokud váš kód plýtvá 1000× více. Optimalizace není předčasná – je záměrná.
Nejde o dokonalost, jde o povědomí. Takže až příště budete nasazovat službu, zeptejte se sami sebe:
- Kolik z tohoto kódu je skutečně potřeba spustit?
- Jak často?
- Za jakou cenu – CPU, paměť nebo energie?
Protože ladění výkonu koneckonců není jen technické – je to etické. Jde o využívání zdrojů s respektem – k vašim uživatelům, vaší společnosti a planetě.
Umění ladění výkonu spočívá v uvědomění si, že efektivita je elegance.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}